成为VIP
成为VIP

统一声明:
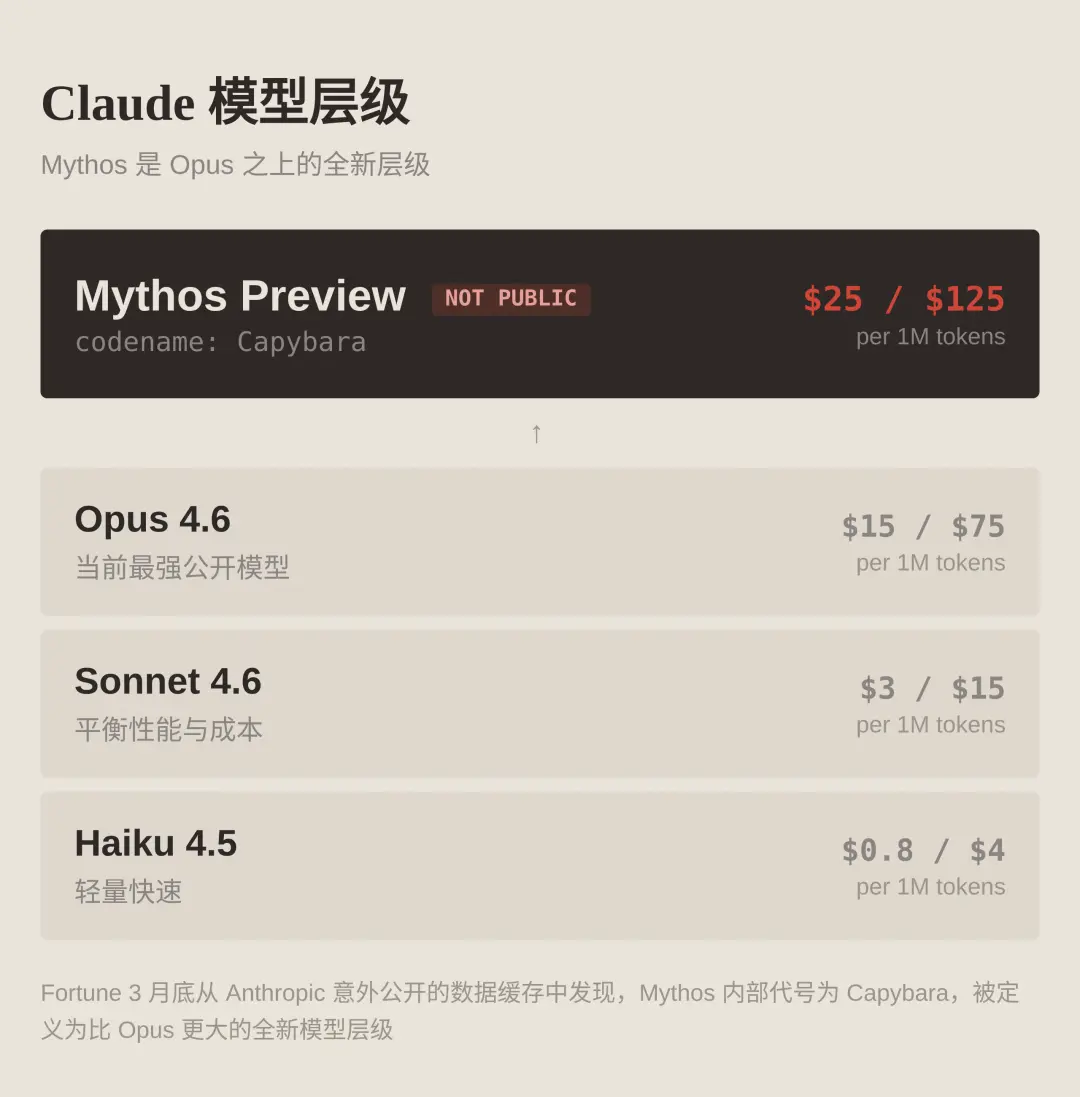
1.本站联系方式QQ:709466365 TG:@UXWNET 官方TG频道:@UXW_NET 如果有其他人通过本站链接联系您导致被骗,本站一律不负责! 2.需要付费搭建请联系站长QQ:709466365 TG:@UXWNET 3.免实名域名注册购买- 游侠云域名 4.免实名国外服务器购买- 游侠网云服务2026年4月3日,谷歌正式发布 Gemma 4,称”这是其迄今为止最智能的开放模型系列”。该系列面向复杂推理与智能体工作流设计,采用商业许可的 Apache 2.0 许可证开源。

Gemma 4 提供四种规格:Effective 2B(E2B)、Effective 4B(E4B)、26B 混合专家模型(MoE)和 31B 稠密模型(Dense)。
端侧部署:手机离线跑 Agent
在端侧,E2B 和 E4B 模型针对移动和物联网设备优化,推理时分别激活约 20 亿和 40 亿参数,以降低内存和电量消耗。据介绍,这两个模型已与谷歌 Pixel 团队、高通和联发科等硬件厂商合作,可在手机、Raspberry Pi、NVIDIA Jetson Nano 等设备上离线运行,延迟接近零。
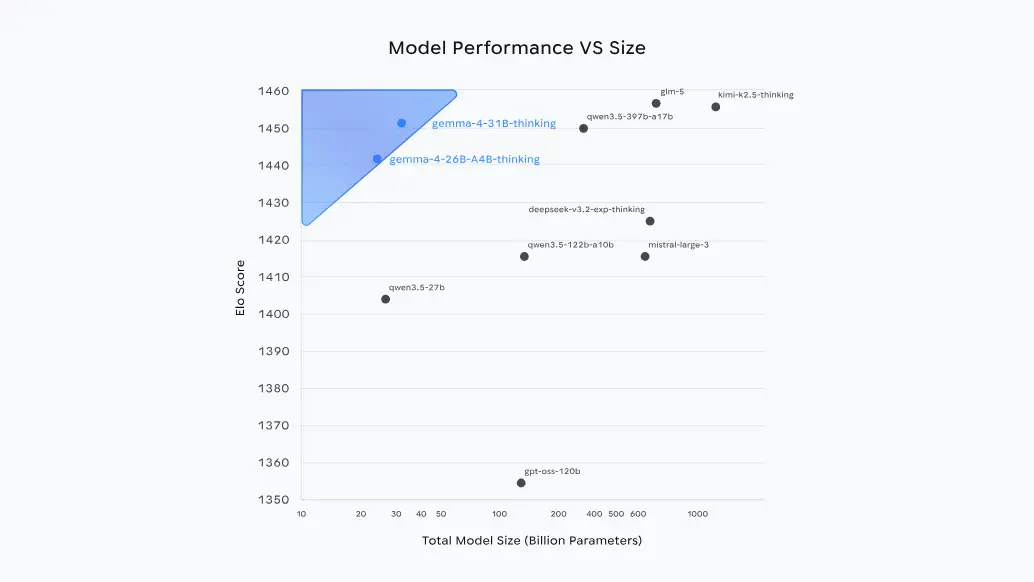
26B MoE 模型有一个巧妙之处:在推理任务中,它只会激活 38 亿参数,因此既能保持较高运行速度,又不会牺牲大模型所具备的深厚知识储备。26B 和 31B 模型提供面向 IDE、编程助手和 Agent 工作流的高级推理能力。
关键提升
Gemma 4 建立在与 Gemini 3 相同的架构基础之上,关键提升包括:
- 推理能力更强:所有模型都面向复杂推理任务进行了优化,并提供可配置的”思考”模式
- 多模态能力扩展:所有模型都支持文本和图像输入;E2B 和 E4B 还原生支持视频与音频输入
- 上下文窗口更大:端侧模型 128K,较大模型(26B/31B)最高 256K
- 编码与智能体能力增强:内置函数调用支持,能够更好地驱动自主 Agent
- 原生支持系统提示词:内置 system role 支持,对话结构更清晰
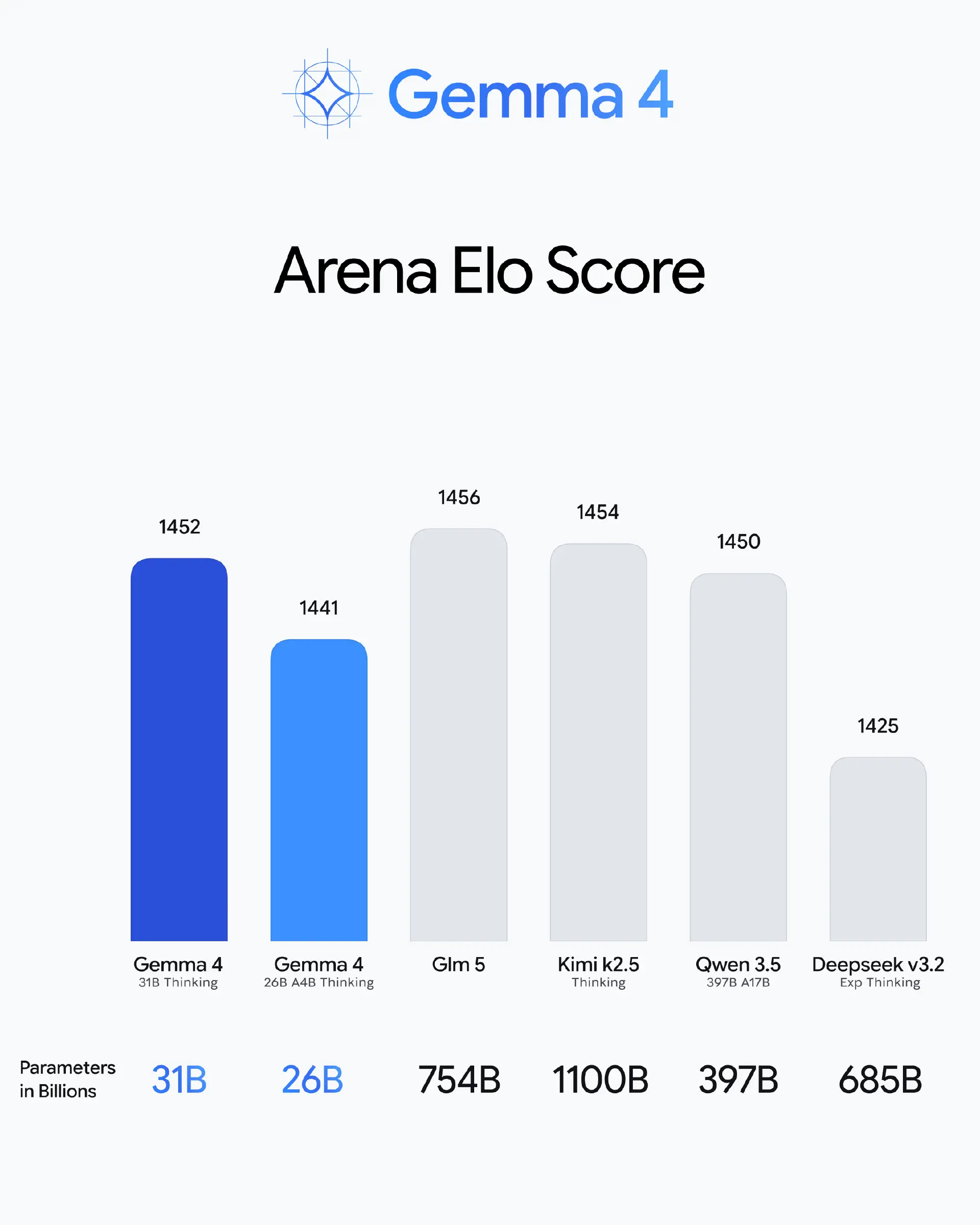
性能越级发挥
谷歌 DeepMind 研究人员 Clement Farabet 和 Olivier Lacombe 表示,在 Gemma 4 上,他们设法进一步压榨出了更多”单位参数智能”,让这些模型能够显著实现”越级发挥”。
根据 Arena AI 文本排行榜,31B 模型排名全球开放模型第 3 位,26B MoE 模型排名第 6 位。谷歌表示,Gemma 4 在部分基准测试中表现优于参数大 20 倍的模型。
有网友评价道:”最让人眼前一亮的部分在于:一共四种尺寸,全部都为 Agent 场景做好了准备,而且全都可以在本地运行。“
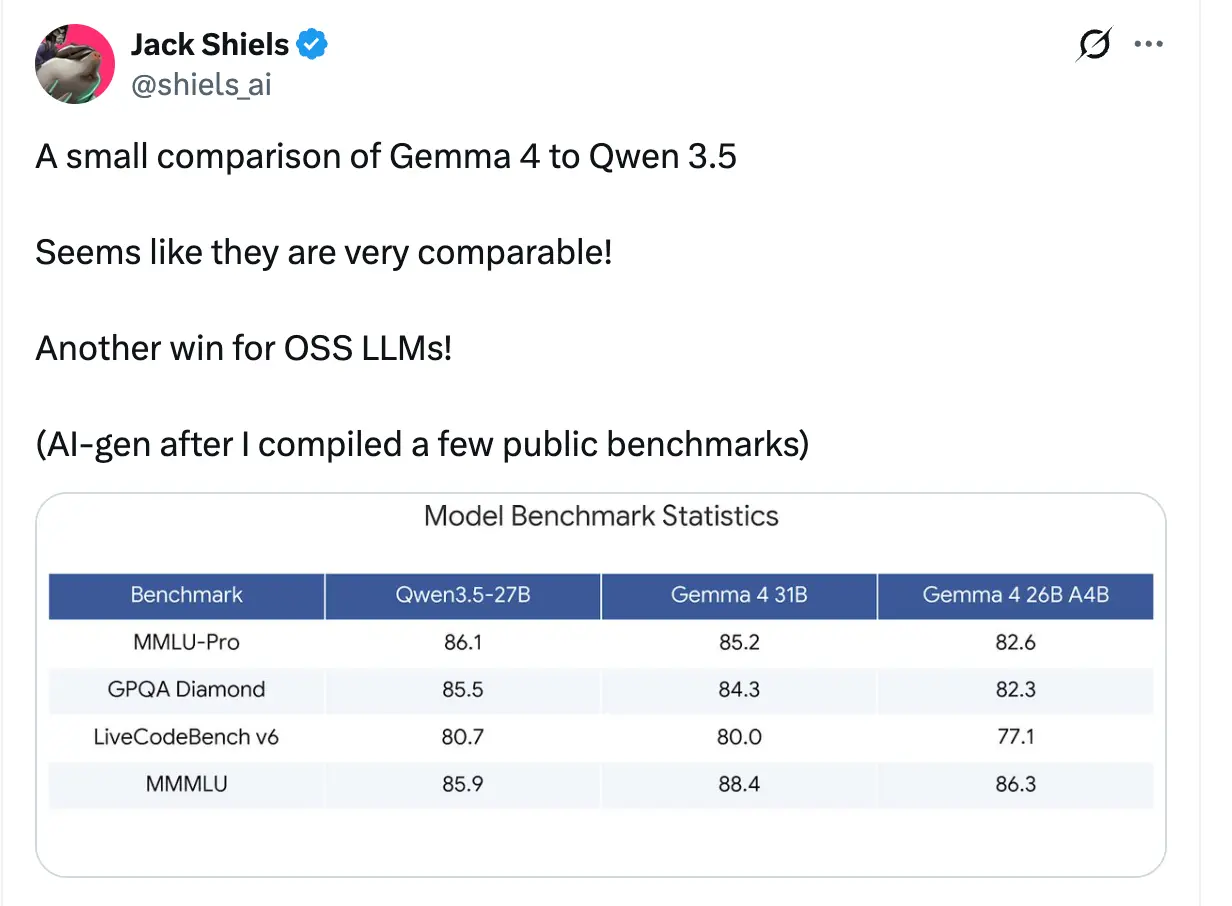
开源+本地,谷歌扩大优势
此次 Gemma 4 采用 Apache 2.0 许可证,允许商业使用、自由修改和部署。谷歌称,这一选择旨在给予开发者对数据、基础设施和模型的完全控制权。
Constellation Research 分析师 Holger Mueller 表示,即便是较大规模的 Gemma 4,也小到足以在单张图形处理器上运行,因此它们非常适合边缘场景。
“谷歌正在扩大自己在 AI 领域的领先优势,不只是依靠 Gemini,也包括通过 Gemma 4 家族这样的开放模型。”
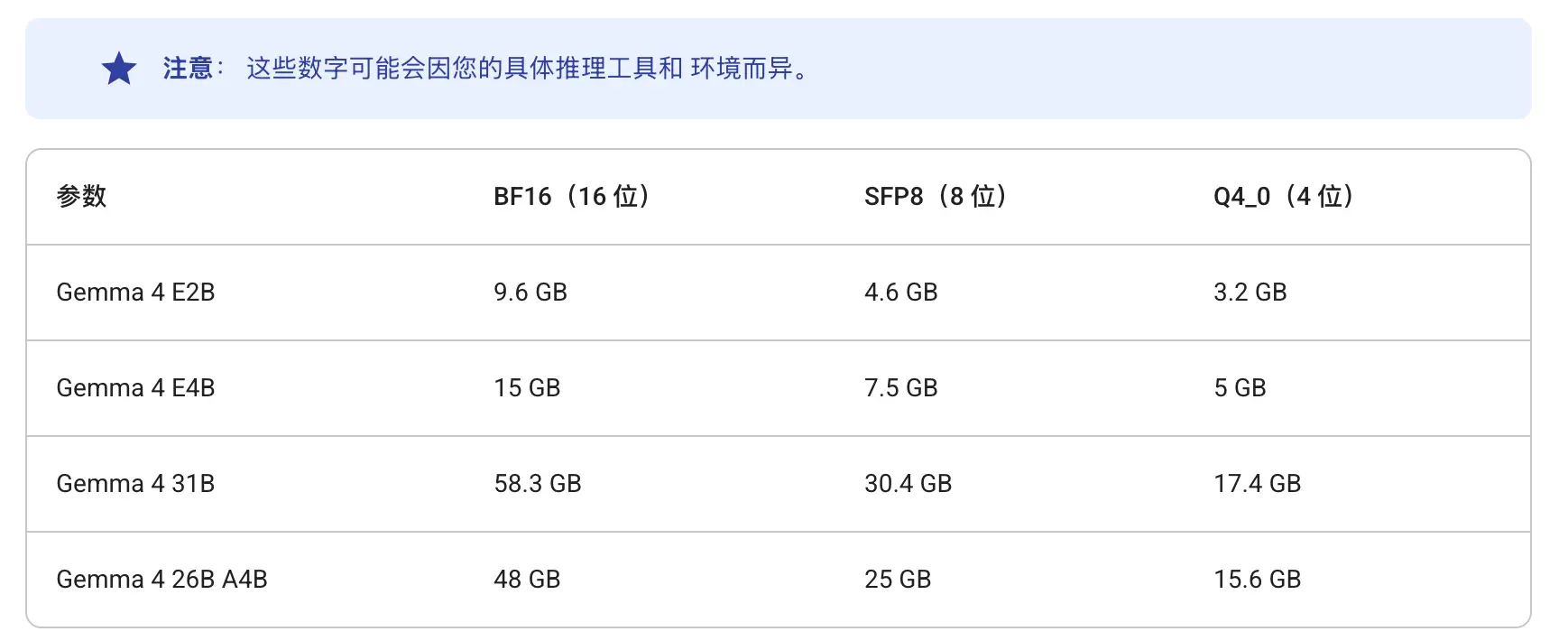
部署路径
开发者可以通过多种途径获取和使用 Gemma 4:
- 平台:Hugging Face、Kaggle、Ollama、谷歌云
- 推理框架:LiteRT-LM、vLLM、llama.cpp、MLX、Ollama、NVIDIA NIM、SGLang
- 硬件支持:NVIDIA、AMD GPU、谷歌 Cloud TPU
不过,也有网友自己测算,Qwen3.5-27B 要略优于 Gemma 4 31B。开源大模型的竞争,正在进入白热化阶段。
来源:InfoQ
2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,请使用WINRAR解压,如遇到无法解压的请联系管理员!
8. 精力有限,不少源码未能详细测试(解密),不能分辨部分源码是病毒还是误报,所以没有进行任何修改,大家使用前请进行甄别!
站长QQ:709466365 站长邮箱:709466365@qq.com