成为VIP
成为VIP

统一声明:
1.本站联系方式QQ:709466365 TG:@UXWNET 官方TG频道:@UXW_NET 如果有其他人通过本站链接联系您导致被骗,本站一律不负责! 2.需要付费搭建请联系站长QQ:709466365 TG:@UXWNET 3.免实名域名注册购买- 游侠云域名 4.免实名国外服务器购买- 游侠云服务📋 背景
在绿洲资本创始合伙人张津剑的一本书中,曾分享过一个MiniMax创始人闫俊杰与DeepSeek创始人梁文锋第一次见面时的小故事。
彼时,梁文锋穿着一件T恤,没有自我介绍,就问了闫俊杰很多技术问题。
“还以为是助理,我想这助理还挺懂的”闫俊杰说,直到半个小时后闫俊杰询问“梁总什么时候来?”才知道对方就是梁文锋。

🔍 详细内容
穿着简单,没有什么老板的架子,对技术很专注,这是梁文锋给外界留下为数不多的印象,他多数时间出现在周围人的描述中,从媒体的报道中可以总结出一个低调神秘、不喜欢参与公司团建、只对编程感兴趣的形象,与传统意义上“明星公司创始人”的画像不同。
拥有这样一位创始人的DeepSeek,也是AI大模型企业中最与众不同的一个。
2024年5月,它靠远低于传统大模型的定价与成本、达到国际顶尖水平的性能、开源技术报告和模型权重,在众星云集的AI大模型赛道中出圈,还引发了行业中的价格战。
它不喜欢开产品发布会、不着急做产品迭代、不跟风加入新兴的赛道、不过分吹捧产品,但不妨碍它依旧位于行业关注的中心。
它不讲商业化故事,身处AI大模型这样一个烧钱做研发的赛道但却并不缺钱,因此,它在过去的很长一段时间中都在拒绝融资,认为资本干预可能会影响技术路线和公司的独立发展。
因此,在近期被传出将进行股权融资的时候,DeepSeek又成了AI圈讨论的焦点。
舆论的发酵甚至赶不上DeepSeek估值增长的速度。自今年4月中旬,被传出将以100亿美元估值释放3%左右股权融资后,DeepSeek的估值已经多次被改写,近期,已经有报道称DeepSeek的估值可能达到500亿美元,三周内翻了5倍。
事情发展至今,故事似乎要向DeepSeek也不得不向巨大的融资额低头的方向行走,但实则不然。DeepSeek对投资者的要求极高,不接受资本对公司有过多干涉,且根据The Information的报道,梁文锋仍在这场融资中占据主导权,其个人出资最高达200亿元人民币,占总募资规模的40%。
很难以行业的共性或者趋势来看待DeepSeek,因为他的掌舵者梁文锋,一直有自己的节奏。
在很多初创企业的叙事里,融资的路径大抵相同:成立-融资-组建团队-发布产品-再融资,最后带着背后的豪华资本朋友圈冲刺上市。
在这个过程中,企业和资本之间通常维持着一种心照不宣的关系:资本向企业提供资金、提出要求;企业出让一部分控制权,但有了继续走下去的底气。
但DeepSeek从成立的第一天起就没按照这个模板行走。外界广泛流传着梁文锋曾给DeepSeek立下的“三不”规矩:不接受外部融资、不稀释股权、不被任何人的商业化时间表绑架。
而这个略显硬核的规矩,在被传出融资消息之前就一直被DeepSeek严格遵守,就算如今第一个“不”已经被打破,不过DeepSeek在寻找资方的过程中,执行着后两个“不”的原则。
近期,市场中流传最多的除了DeepSeek的融资动作、估值变化等,还有一些资本被梁文锋拒之门外的消息。
其中被广泛讨论的是DeepSeek与阿里和腾讯之间的谈判。
这两家互联网大厂正在洽谈投资DeepSeek的消息大约在4月23日前后被大量媒体提及,根据《财经》的报道,当时一位接近交易的人士透露,腾讯与阿里巴巴两家投资方预计共计投资18亿美元,DeepSeek的估值超过了200亿美元。
不过到了5月,两家企业均被曝出在谈判中失利,不是因为钱不到位,而是因为他们都试图从DeepSeek手中拿到更多的话语权,这触碰了梁文锋的底线。
而据白鲸实验室报道,阿里与DeepSeek的投资已经谈崩,核心分歧在于阿里希望在AI战略上构建闭环生态,而DeepSeek坚持技术独立,拒绝了生态绑定的条件。
不过对于这个消息,市场上还出现了另一种声音:根据《每日经济新闻》在5月9日的报道,有市场人士透露,阿里应该没有进行谈判。
另据彭博社报道,有知情人士透露,腾讯提出在本轮融资中认购DeepSeek最多20%的股份。但这一样没有被梁文锋采纳。
此后,外媒The Information报道称,梁文锋将个人出资最高达200亿元人民币,占本轮计划融资总额40%,这个消息更是印证了梁文锋在这轮融资中,决不出让主动权的强硬态度。

报道还透露出腾讯已经更换了投资方式的消息,一位知情人士透露,“腾讯出资60亿,占约2%股权。”
拒绝互联网大厂抛来的橄榄枝,并自掏腰包占据融资主导权,梁文锋的融资逻辑实则一直与钱无关。
DeepSeek不缺钱,其背后是梁文锋创立的量化公司——幻方量化。
据私募排排网数据,2025年,幻方量化的平均收益率高达56.6%,管理规模超700亿元。业内人士估算,仅2025年幻方量化就为梁文锋带来了超过7亿美元的收入,这几乎构成了,DeepSeek独立运转的“弹药库”。
而梁文锋这次选择在融资上“松口”,是因为DeepSeek技术的基本盘——人才,在近期经历了不小的动荡。
2025年底至2026年初,就先后有DeepSeek-V2架构的关键贡献者罗福莉、第一代大语言模型核心作者王炳宣、R1核心作者郭达雅等核心人才离开DeepSeek,转投他厂。
梁文锋最在意的,不会是能否拿到更多融资、能否与互联网大厂建立合作、能否吸引更强大的资本……而是如何在竞对高薪“挖角”的环境下,留住自己的核心技术人员。

因此,他的这次融资,或许是希望通过外部资本给公司作出一个较为公允的估值,让DeepSeek员工手中的期权在定价上更有吸引力。
在DeepSeek最新产品DeepSeek-V4的技术报告里,写着一份长长的作者致谢名单,研究工程团队约270人中,只有10人在研发期间离去。对应下来,技术研发人员离职率不到4%,意味着梁文锋成功留住了97%的员工。
这些人,将继续按照梁文锋的思路,走向与众不同的道路。
尽管有关DeepSeek融资的细节铺天盖地,但梁文锋与DeepSeek都没有对此进行过公开回应。反而是在此期间的4月24日,这家公司在没有任何预热的情况下,悄悄上线了行业等待了5个月的新产品——DeepSeek-V4预览版。
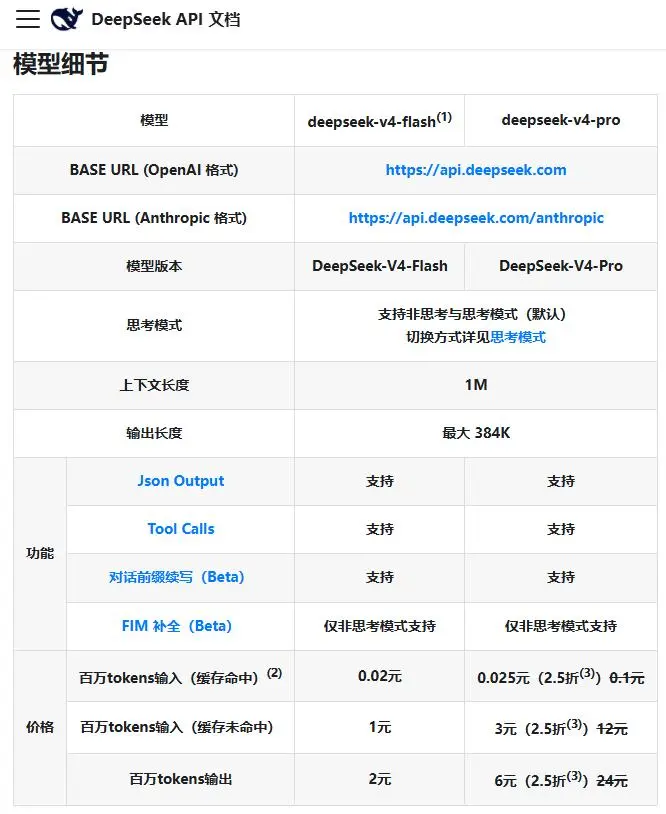
按照DeepSeek的介绍,DeepSeek-V4拥有百万字超长上下文,在Agent能力、世界知识和推理性能上均实现国内与开源领域的领先。
更引发市场讨论的是这款产品的定价。
这样的定价之所以引发关注,是因为DeepSeek-V4的核心优势——超长上下文极其消耗计算量。据了解,标准的Transformer注意力,每个token都要和前面所有token做一次计算。而上下文从8K扩展到1M,其计算量将是平方级的增长。

而DeepSeek却能在这样的情况下依旧保持低价策略,这并不是一件容易的事。
如果对比同期OpenAI发布的最新产品GPT-5.5,DeepSeek定价的优惠程度则更为直观。
以API价格为例,GPT-5.5的标准报价为输入每百万Token 5美元、输出每百万Token 30美元;DeepSeek-V4-Pro在2.5折促销期内的报价为缓存命中输入每百万Token0.025元、缓存未命中输入每百万Token 3元、输出每百万Token 6元。
如果按1美元约合7.2元人民币粗略折算,GPT-5.5的输出价格约为每百万Token 216元,是DeepSeek-V4-Pro促销价的30多倍。
而DeepSeek降价的另一边,在算力成本逐渐提高的情况下,涨价和收费已经成为大模型企业不得不做出的现实选择。
例如GPT-5.5的价格比GPT-5.4整体贵了一倍;智谱AI在4月初公布了今年以来的第三次提价计划,发布新一代旗舰模型GLM-5.1的同时提价10%;Kimi在4月下旬发布K2.6时,将API输入价格从0.60美元/百万Tokens上调至0.95美元/百万Tokens,涨价58%。
一边是行业整体的涨价趋势,另一边则是梁文锋与DeepSeek的逆势降价,场面似乎与两年前惊人地相似,彼时,性价比极高的DeepSeek还意外引发了大模型行业的价格战。

之所以说是“意外”,是因为梁文锋无意引发价格战,他曾在接受36氪的采访时表示,自己对掀起行业价格战一事非常意外,“我们只是按照自己的步调来做事,然后核算成本定价。”
但也与两年前一样,这一次DeepSeek-V4也无意引发价格战,其能逆势降价、把控好成本,是靠技术创新实现的。
其中,DeepSeek-V4成本压缩的核心突破在于压缩注意力机制的改善。
其设计了压缩稀疏注意力(CSA)和重度压缩注意力(HCA)两种压缩注意力机制,前者负责精准定位关键细节,后者负责把握全局脉络。
DeepSeek将两种注意力在前向传播中每一层交替使用,将Prefill阶段的注意力计算复杂度从O(N^2)降低为近似线性的O(N*k),并线性压缩了Prefill和Decode阶段的KV Cache,减少了推理时显存和带宽的压力。
在这些层层削减之后,缓存体积已经被压缩到了90%以上。
除此之外,DeepSeek降低成本的方式还有很多。

例如其靠一套动态稀疏选择机制,将复杂度强制截断为常数级运算。在1M长上下文下,V4 Pro的单token推理FLOPs降到了前代V3.2的27%;其自研的TileLang语言,能让GPU计算与网络传输并行,硬件利用率逼近极限;针对智能体任务,用特殊标记替代额外小模型,直接复用主模型的KV Cache来并行执行一些辅助任务。把推理成本压到极致。
“我们的原则是不贴钱,也不赚取暴利。这个价格也是在成本之上稍微有点利润。”这是梁文锋在DeepSeek-V2引发价格战后对媒体的回应,这也同样适用于DeepSeek-V4。
对于梁文锋来说,其他企业的定价如何,并不能成为他的参考依据,他只专注在自己的技术逻辑上,开出适用于DeepSeek的定价。
💡 分析与影响
如果经历过从DeepSeek-V3.2,到DeepSeek-V4之间那5个月的漫长等待,这个答案可能呼之欲出。
在DeepSeek沉默的这五个月期间,不管是美国市场的OpenAI、Anthropic、谷歌Gemini,还是中国市场的阿里千问、字节跳动豆包、腾讯混元、小米MiMo等主流模型公司,都至少发布或迭代了多款模型,几乎每2.8天就会有一款模型发布或迭代。
对于AI大模型公司而言,商业化几乎是与产品迭代相伴相生的话题。企业们害怕自己的技术被赶超,害怕失去商业化优势,进而失去自己在资本市场的想象力。
而长期不着急迭代的DeepSeek,在那段时间就已经开始被超越了。DeepSeek-V3.2的性能一度在国际市场调研机构Artificial Analysis的基准测试中,落后于penAI、Anthropic、谷歌Gemini、阿里千问、月之暗面Kimi、智谱GLM、MiniMax等旗舰模型。
更关键的是行业中掀起龙虾热后,Agent需求也随之爆发,Coding能力成为各家企业追逐的方向,而DeepSeek-V3.2,在Agent和Coding能力上也显得相对落后。
但不管其他企业的模型如何迭代、市场对DeepSeek的失望情绪有多高,这些似乎都很难影响到梁文锋与DeepSeek的开发节奏。
梁文锋有自己的坚持,在他为数不多的采访中,“实现AGI”、“不追求短期的商业化”是其反复提及的观点。
将大模型的底层技术做到极致,才是梁文锋的追求。
DeepSeek-V4一经发布,就在很大程度上追平了前代作品在Agent方面的落后趋势。

DeepSeek在发布公告中表示,相比前代模型,DeepSeek-V4-Pro在AgenticCoding评测中,已达到当前开源模型最佳水平,并在其他Agent相关评测中表现优异;在世界知识测评中,大幅领先其他开源模型;在数学、STEM、竞赛型代码的测评中,超越当前所有已公开评测的开源模型,并取得了比肩世界顶级闭源模型的成绩。
DeepSeek-V4此次更新升级的核心能力之一——上下文,是Agent工具理解并记忆大量文本的关键,而DeepSeek此次发布的两个模型都能支持100万token的上下文长度,这将大大提升Agent阅读文本、记住更多细节的能力。
根据差评的测试,将一本红楼梦中随便贴了一段三体的科幻小说内容发送给DeepSeek-V4查找异常,它用几秒钟就找到了。
另一个细节也体现了梁文锋与DeepSeek不强调全球领先、将底层技术做到极致的态度——在产品的发布公告中承认自己与竞对存在的差距。
其表示,目前DeepSeek-V4已成为公司内部员工使用的Agentic Coding模型,据评测反馈使用体验优于Sonnet 4.5,交付质量接近Opus 4.6非思考模式,但仍与Opus 4.6思考模式存在一定差距。
对于AI行业已经说了很长时间的多模态故事,DeepSeek也是慢慢来的态度。
如今的DeepSeek-V4仍未搭载原生多模态能力,目前只有市场消息透露,其将在今年6月推出的V4模型迭代版本——V4.1会新增图像、音频理解处理能力,但输出形式仍仅限文本生成。
种种迹象都在表明,如果没有将产品的技术水平做到极致,外部市场动态与声音,撼动不了梁文锋的研发节奏和目标。
2024年,梁文锋曾在36氪的采访中表达过这样一个观点,“过去三十年,我们都只强调赚钱,对创新是忽视的。创新不完全是商业驱动的,还需要好奇心和创造欲。”

两年过去,梁文锋鲜少再对外发声,但很明显,他不想让商业驱动创新的态度,直到现在都没变。
2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,请使用WINRAR解压,如遇到无法解压的请联系管理员!
8. 精力有限,不少源码未能详细测试(解密),不能分辨部分源码是病毒还是误报,所以没有进行任何修改,大家使用前请进行甄别!
站长QQ:709466365 站长邮箱:709466365@qq.com