
 成为VIP
成为VIP

统一声明:
1.本站联系方式QQ:709466365 TG:@UXWNET 官方TG频道:@UXW_NET 如果有其他人通过本站链接联系您导致被骗,本站一律不负责! 2.需要付费搭建请联系站长QQ:709466365 TG:@UXWNET 3.免实名域名注册购买- 游侠云域名 4.免实名国外服务器购买- 游侠云服务📋 背景
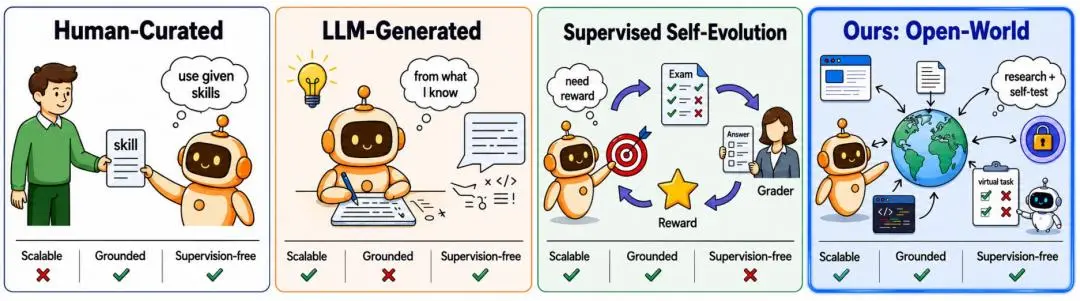
目前,自进化 Agent 的持续学习,大多数依赖成功轨迹、现成 skills 或明确反馈。但在真实部署中,Agent 也因这些前提难以同时满足,无法继续积累经验并迭代。
针对这个问题,里海大学计算机科学与工程系助理教授孙立超团队及其合作者提出了 OpenSkill框架——不同于依赖人工策划、LLM 生成或监督信号的自进化方法,让 Agent 在不依赖目标任务监督信号的情况下,也可获得可执行、可迁移的 skills。
论文链接:https://arxiv.org/abs/2606.06741

🔍 详细内容
结果显示,OpenSkill 在多个基准上取得 SOTA 自动化表现,学到的 skills 还可直接迁移到能力更弱的模型。相关资源已在 GitHub 上公开,供免费下载、使用。
图|自进化 Agent skills 的范式。

OpenSkill 是一个面向开放世界的 Agent skills框架,它以任务指令、执行环境、基础模型、工具访问权限和开放世界资源为输入,整体流程包括三步:开放世界知识获取、无泄漏 skills 进化和零样本目标评估。
图|OpenSkill 框架概览。
开放世界知识获取:研究团队首先从开放世界中检索两类信息:一类是任务知识,包括背景概念、API 文档、最佳实践和源码示例,用于形成 skills 规划;另一类是验证知识,包括参考值、统计不变量、交叉验证流程以及已知输入输出样例,用于支撑后续虚拟测试。
无泄漏 skills 进化:在获得任务知识和验证知识后,OpenSkill 会先生成候选 skills,再通过自动构造的虚拟任务反复测试、筛选和改进。整个过程不使用目标任务的标准答案,真实测试集也不会提前进入 skills 构建阶段。
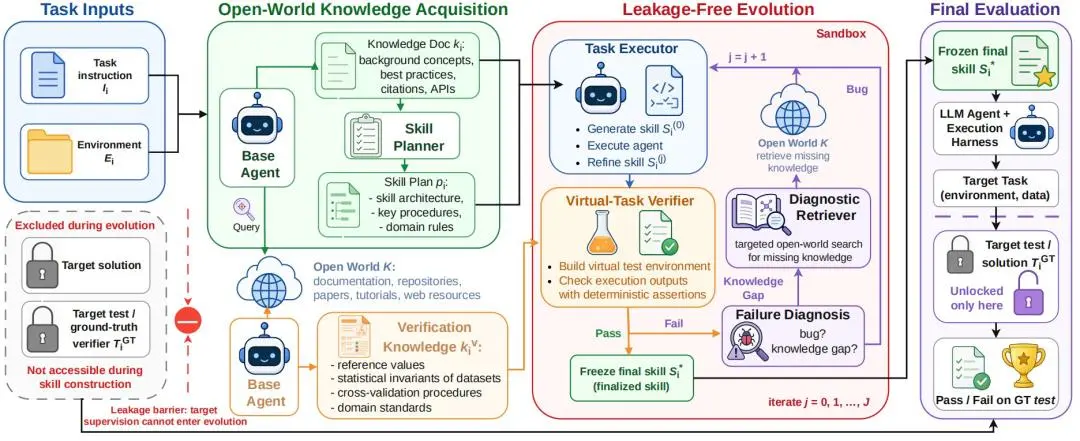
零样本目标评估:skills 进化完成后,最终会以显式文件的形式部署到目标 Agent 上。隐藏的真实测试集仅在这一阶段用于最终评估,不参与此前的 skills 构建和迭代。
为验证 OpenSkill 的有效性,研究团队从 benchmark 表现、skills 迁移和消融实验方面进行了评估。实验结果如下:
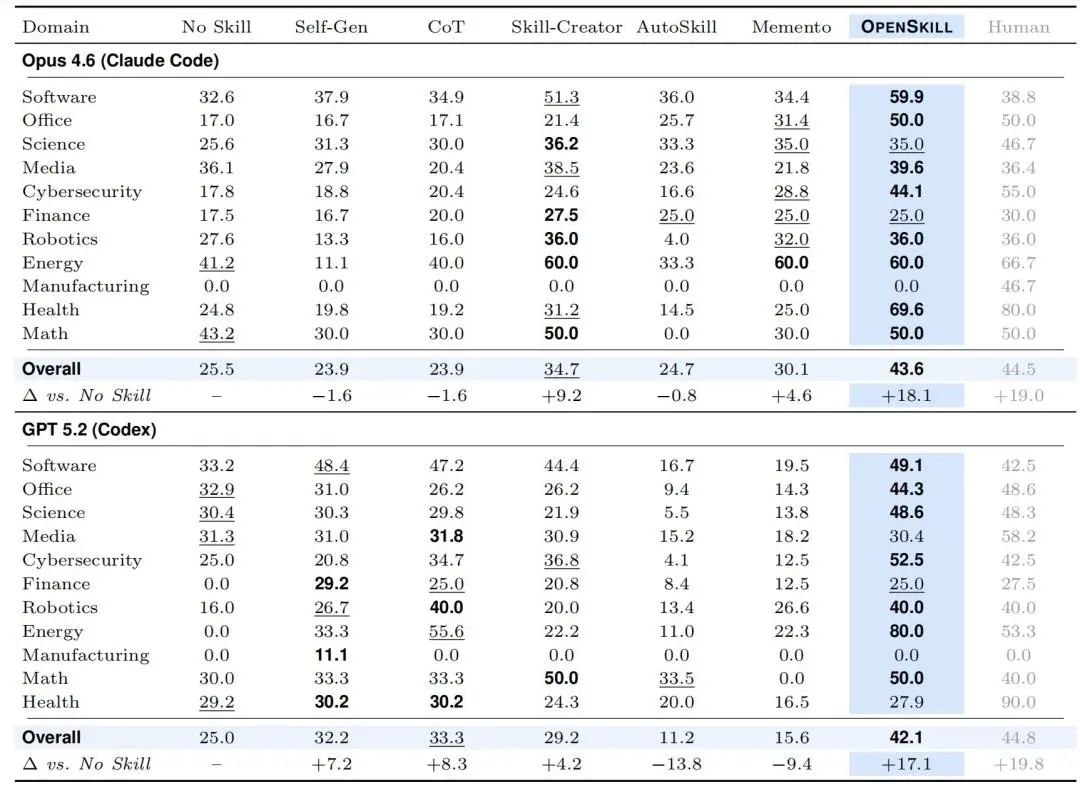
1.benchmark 评测:OpenSkill 总体成绩领先
OpenSkill 在三个 benchmark、两个目标 Agent 上均取得了最佳自动化表现。在 SkillsBench 上,它将 Opus 4.6 和 GPT 5.2 的总体通过率分别提升至 43.6% 和 42.1%,较最强基线高出 8.9 和 8.8 个百分点,距离人类参考上限仅差 1 至 3 个百分点;其中在 Opus 4.6 上,11 个领域中有 8 个达到最佳或并列最佳。
图|SkillsBench在 11 个领域的主要结果:展示了两个目标 Agent 在各领域上的平均奖励。
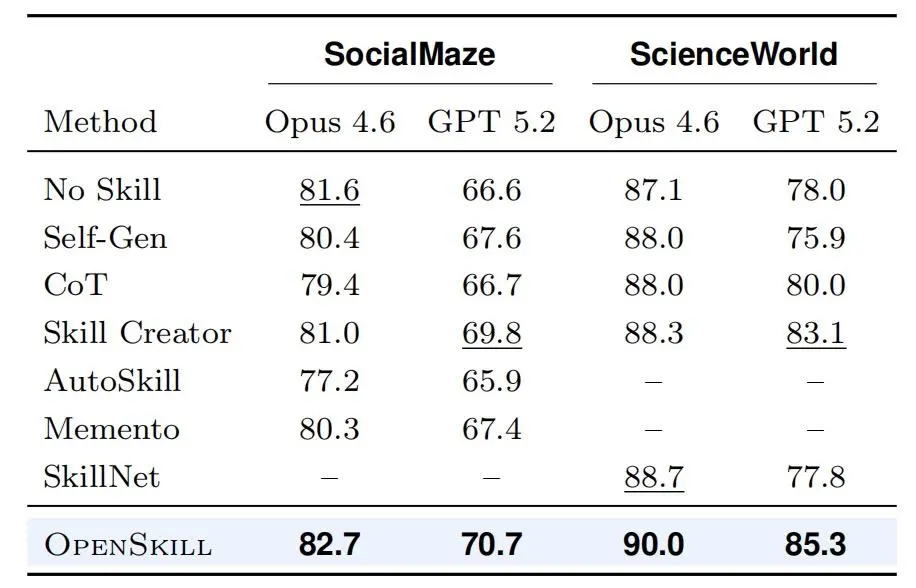
类似结果也出现在另外两个 benchmark 上。在 SocialMaze 中,OpenSkill 在 Opus 4.6和 GPT 5.2 上的通过率分别达到 82.7% 和 70.7%;在 ScienceWorld 中,这两个数字分别达到 90.0% 和 85.3%。研究团队指出,在这四组设置中,OpenSkill 均为表现最好的自动化方法。
图|两个目标 Agent 在 SocialMaze 和 ScienceWorld 上的平均奖励。
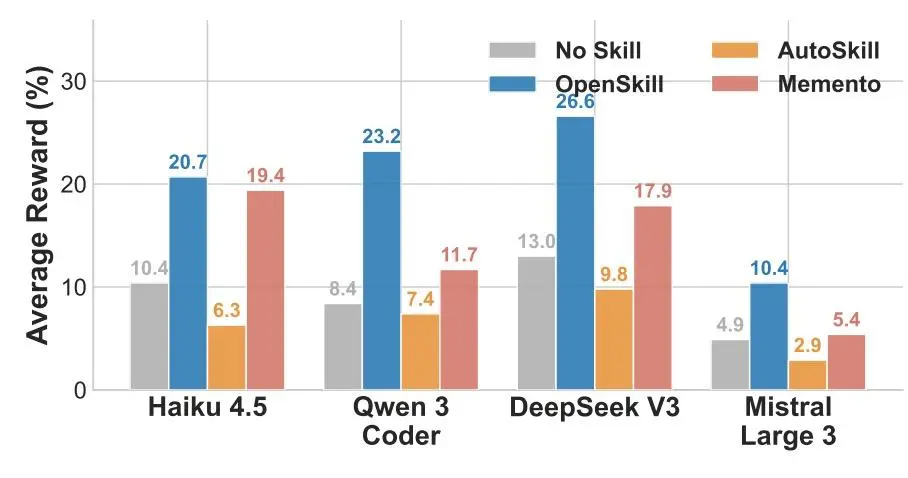
2.Skills 迁移:无需额外适配即可迁移到更弱模型
skills 迁移方面,研究团队将由 Opus 4.6 生成的 skills 直接迁移到 Haiku 4.5、Qwen 3Coder、DeepSeek V3 和 Mistral Large 3 四个更弱模型上,无需额外适配。结果显示,这些 skills 在四个目标模型上都带来了明显增益,较无 skills 基线提升 5.5 至 14.8 个百分点。
💡 分析与影响
图|由 Opus 4.6 生成的 skills 迁移到其他模型后,在 SkillsBench 上获得的平均奖励。
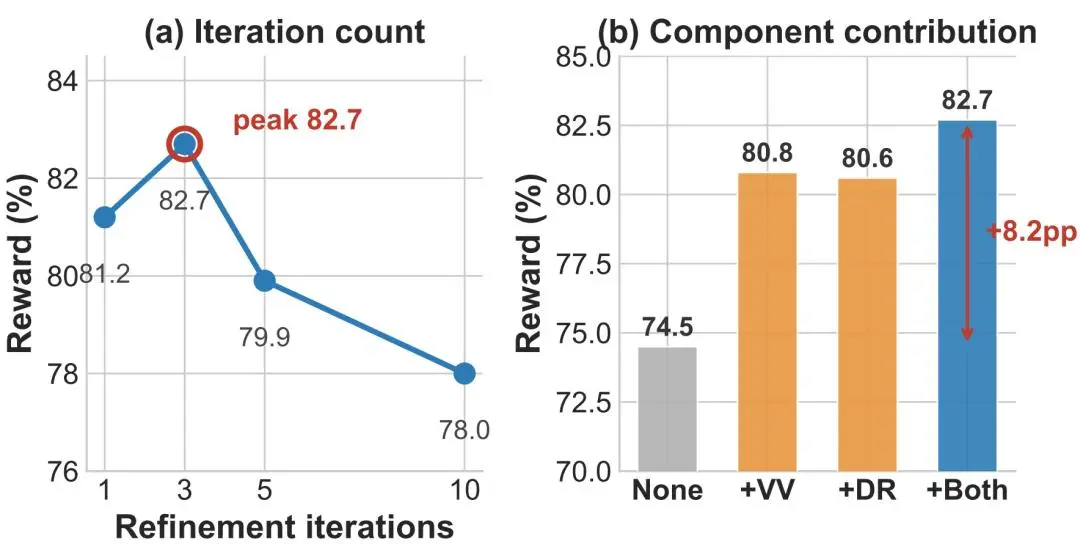
在 SocialMaze 上,OpenSkill 在 3 轮迭代时达到最高 82.7%,继续增加到 5 轮和 10 轮后,效果反而下降。消融结果还显示,开放世界检索和虚拟验证器都能单独提升表现,结合使用时效果最好。研究团队进一步发现,虚拟验证器与真实评测结果存在明显一致性,能够覆盖 88.9% 的真实测试意图,还会补充格式、类型和边界条件等检查。
图|SocialMaze 上的消融实验。

不过,研究团队也指出,开放世界知识源本身可能存在噪声、过时或相互冲突的信息;虚拟任务也难以完全还原真实任务的复杂度,针对深层语义验证和反作弊元验证的覆盖仍然有限。
此外,该方法成本昂贵且耗时较长。SkillsBench 的 84 个任务上,端到端 API 总成本约为 1800 美元;单任务平均消耗约 1.14M tokens,耗时约 131 分钟。不过,skills 创建只需做一次,后续迁移到其他模型时无需重建。
研究团队表示,未来需重点提升知识源的可信度,增强虚拟任务对真实任务的覆盖能力,并进一步降低整体成本与时延。

2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,请使用WINRAR解压,如遇到无法解压的请联系管理员!
8. 精力有限,不少源码未能详细测试(解密),不能分辨部分源码是病毒还是误报,所以没有进行任何修改,大家使用前请进行甄别!
站长QQ:709466365 站长邮箱:709466365@qq.com



