
 成为VIP
成为VIP

统一声明:
1.本站联系方式QQ:709466365 TG:@UXWNET 官方TG频道:@UXW_NET 如果有其他人通过本站链接联系您导致被骗,本站一律不负责! 2.需要付费搭建请联系站长QQ:709466365 TG:@UXWNET 3.免实名域名注册购买- 游侠云域名 4.免实名国外服务器购买- 游侠网云服务OpenClaw 8 大模型实测对比:GPT-5/Claude/Gemini/DeepSeek 谁最强?(2026)
测试方法论
每个维度准备了 30+ 个测试 case,覆盖简单、中等、困难三个档次。不用公开 benchmark(那些早被模型训练数据污染了),用的是实际业务场景构造的测试题。
推理能力决定了模型能不能”想明白”复杂问题。我们测了数学计算、逻辑推理、因果分析、多步骤规划四类题目。
8 大模型速览
OpenClaw 最常见的用途之一是写代码。测试涵盖函数生成、Bug 修复、代码重构、测试用例编写。
工具调用(Function Calling)是 AI Agent 的核心能力——模型能不能正确理解该调哪个工具、传什么参数、处理返回结果。
维度一:推理能力

OpenClaw 执行任务时会多轮调用模型,每一轮的延迟都会累积。我们测了首 token 延迟(TTFT)和生成吞吐量(tokens/s)。
注:以上数据基于 Ofox 国内加速节点测试,直连海外 API 延迟会更高。
维度二:代码生成
成本直接影响 OpenClaw 的长期使用意愿。统一换算为 $/百万 token(参考各平台官方定价)。
注:价格参考各厂商 2026 年 3 月官方定价,实际使用中会因缓存命中、批量折扣等有所变化。通过 Ofox 接入时价格与官方基本一致。
维度三:工具调用
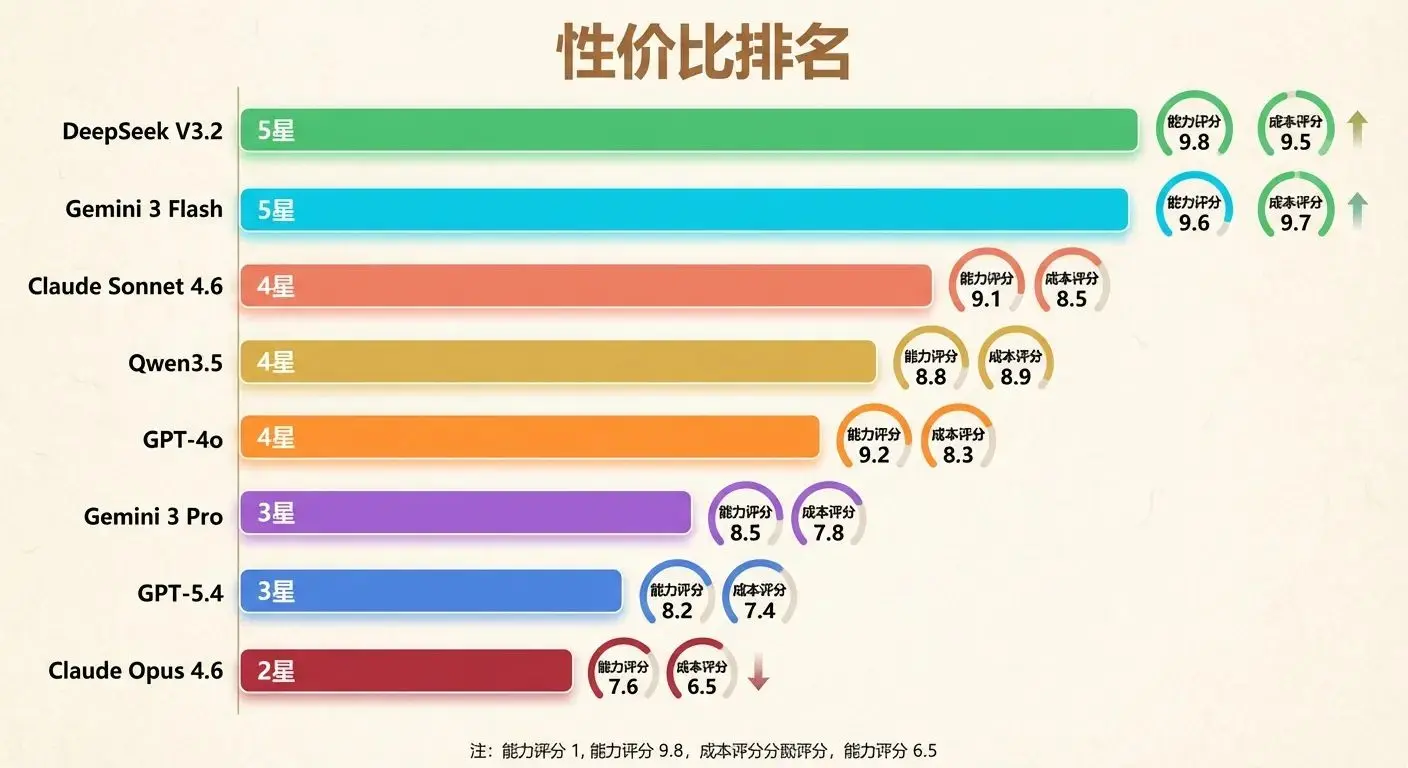
性价比 = 综合能力 / 成本。以下排名考虑了”每花一块钱能买到多少能力”:
DeepSeek V3.2 和 Gemini 3 Flash 的性价比领先,80% 的日常任务用它们就够了。旗舰模型留给真正需要的时刻。
维度四:响应速度
取决于场景。综合能力最强是 Claude Opus 4.6 和 GPT-5.4,性价比最高是 DeepSeek V3.2,速度最快是 Gemini 3 Flash。建议参考本文的场景推荐矩阵选择。
GPT-5.4 在数学推理、多模态理解和工具调用上更强;Claude Opus 4.6 在代码生成、长文本理解、中文处理上更优。建议根据主要任务类型决定。
维度五:成本
对于 80% 的日常任务完全够用。综合能力接近 GPT-4o,中文理解甚至更好,价格只有 GPT-4o 的六分之一。短板在复杂工具调用和超长推理链,这些场景建议升级旗舰模型。
取决于使用频率和模型选择。全用旗舰模型约 300-800 元/月;混合策略(日常 Sonnet + 复杂任务 Opus)约 100-250 元/月;以 DeepSeek 为主约 30-80 元/月。
五维度大横评总表
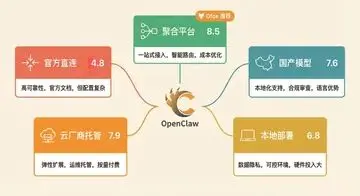
在 OpenClaw 的配置文件中设置 primary model 和 fallback model。通过聚合平台只需修改模型名称参数即可切换,不用改 API Key 和 base_url。也可以通过 /model 命令在运行时动态切换。
GPT / Claude / Gemini 低延迟专线接入,3 分钟跑通第一个调用
场景推荐矩阵
性价比排名
OpenClaw 最佳模型配置方案
常见问题(FAQ)
📰 来源:OfoxAI | 作者:OfoxAI
🔗 原文链接:https://ofox.ai/zh/blog/openclaw-8-models-benchmark-comparison-2026/
2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,请使用WINRAR解压,如遇到无法解压的请联系管理员!
8. 精力有限,不少源码未能详细测试(解密),不能分辨部分源码是病毒还是误报,所以没有进行任何修改,大家使用前请进行甄别!
站长QQ:709466365 站长邮箱:709466365@qq.com



