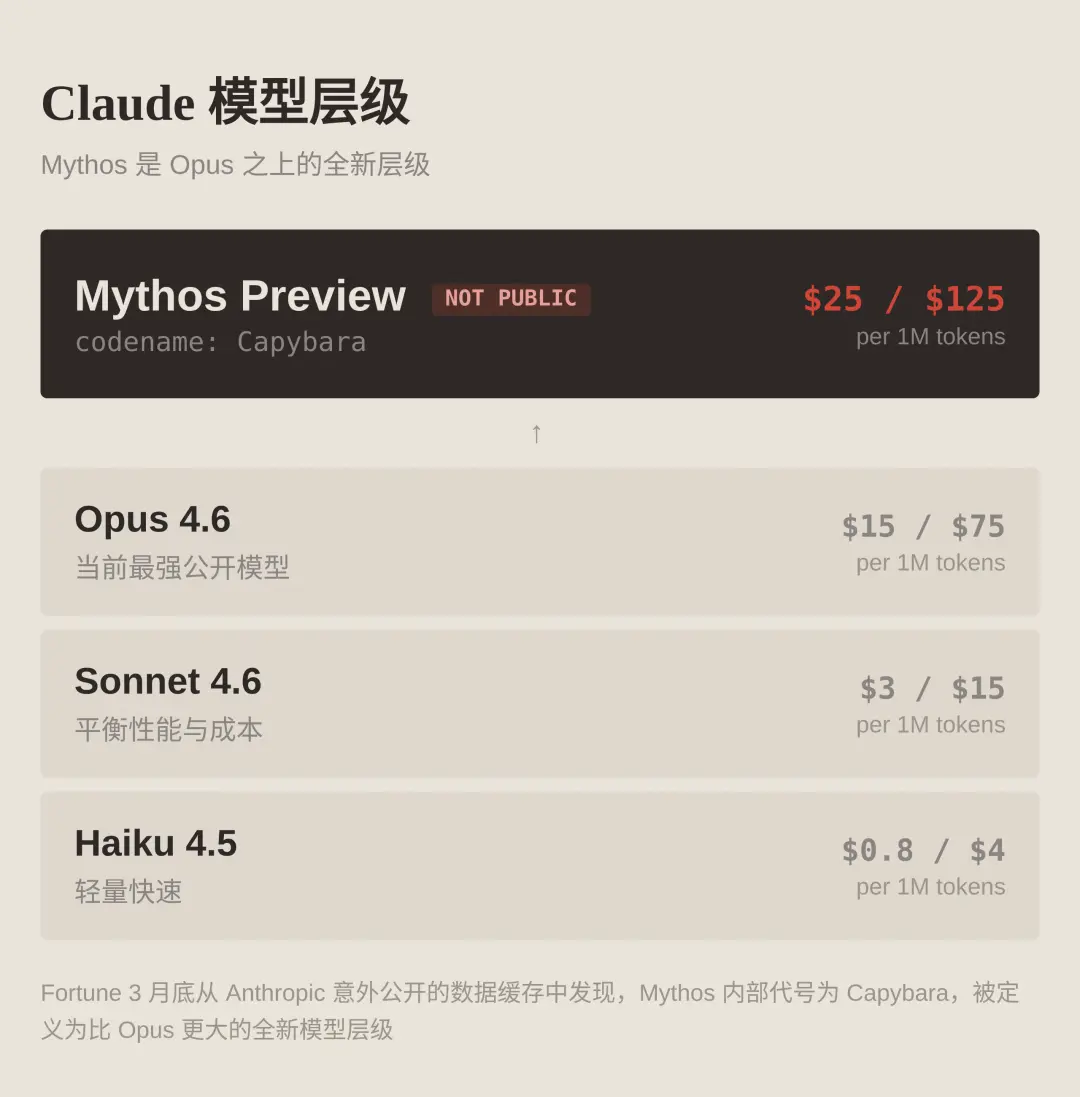
成为VIP
成为VIP

统一声明:
1.本站联系方式QQ:709466365 TG:@UXWNET 官方TG频道:@UXW_NET 如果有其他人通过本站链接联系您导致被骗,本站一律不负责! 2.需要付费搭建请联系站长QQ:709466365 TG:@UXWNET 3.免实名域名注册购买- 游侠云域名 4.免实名国外服务器购买- 游侠网云服务【导读】一个让AI像原始人一样说话的插件,在HN上一夜爆火,冲破2w星。它的核心只是一条简单粗暴的prompt:删掉冠词、客套和一切废话,号称能省下75%的输出token。它能火,说明开发者已经受够AI话痨了。
最近,一个叫「caveman」(穴居人)的Claude Code插件,在Hacker News炸了。
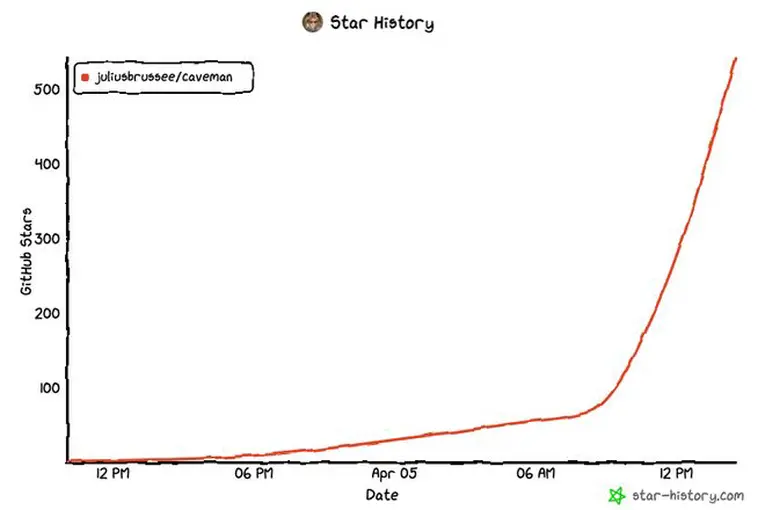
从这条GitHub star增长曲线来看,「JuliusBrussee/caveman」在最初很长一段时间里几乎只是缓慢爬升,随后陡然上扬:短短半天左右,star数从几十一路冲到500,目前已冲破2w!
「穴居人」省Token技能爆红

caveman一夜爆火背后,其实是一次典型的社区情绪共振。它意味着「AI Yap(废话连篇)」,这个看上去很小、却让无数人早已破防的痛点,再次被人精准地捅破了。
很快就有网友把caveman称作「2026年最厉害的提示词技巧」,称它能够砍掉浪费在「我很乐意帮你」这种礼貌和铺垫上的token。
这个插件干的事其实很简单
让AI agent像洞穴人一样说话。删掉「the」「please」「thank you」……删掉一切不影响技术含义、却不断吞噬token的「人类客套」。
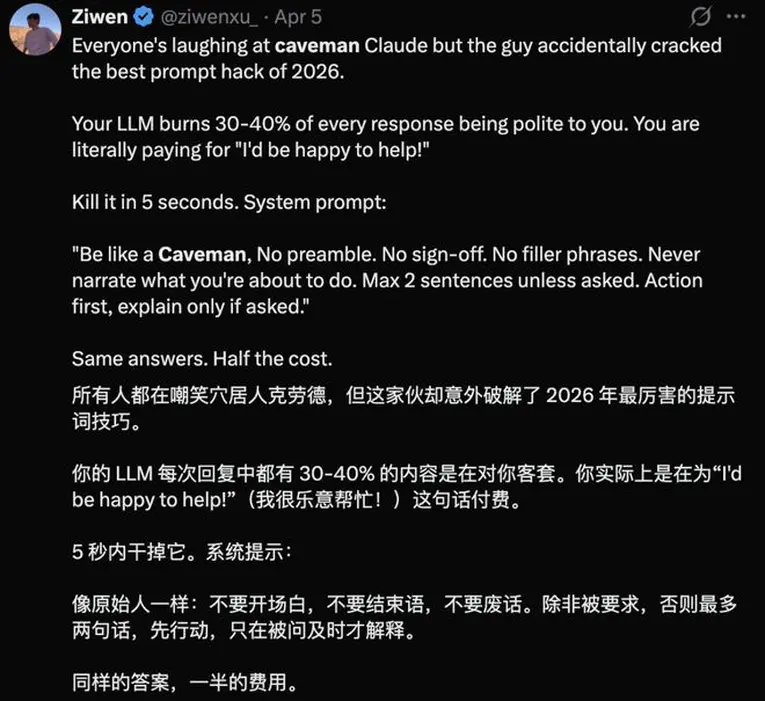
项目出自开发者Julius Brussee之手,GitHub仓库名为「JuliusBrussee/caveman」。Julius在README里抛出的核心问题也非常直接:为什么少量token能说清楚的事,要用那么多token去说?
这是一款同时适配「Claude Code」和「Codex」的技能/插件。它的核心思路是让智能体像「原始人」一样开口,在不牺牲技术准确性的前提下,把输出压缩到极致,并声称可将token消耗降低约75%。
扒开SKILL.md,网友傻眼,就这?
caveman到底怎么「省」的?打开它的核心文件SKILL.md,内容确实不长。

文件frontmatter直接把它定义成「Ultra-compressed communication mode」(超压缩通信模式)。并写明:通过像洞穴人一样说话,在保持技术准确性的前提下,目标是把token用量压到更低。
当用户说出「caveman mode」「talk like caveman」「use caveman」「less tokens」「be brief」,或调用「/caveman」时启用。
节省「token」的规则也非常简单粗暴:
- 删除以下内容:冠词、语气填充词、客套话、犹豫性表达
- 允许使用短句、碎片句
- 优先使用更短的同义词,说「大」而不是「庞大」,说「修」而不是「实施一个解决方案」
- 技术术语必须保持精确
- 代码块不改
- 报错信息必须原样引用
- 推荐句式:[问题][动作][原因]。[下一步]
比如,不要这样写:「当然!我很乐意帮你。你遇到的问题,很可能是由……引起的……」
而是要这样写:「Bug在认证中间件。Token过期判断用了<,没用<=。改这里:」
三档强度级别
它支持三档强度级别:lite、full(默认)、ultra。
lite:去掉填充词和犹豫表达。保留完整句子和正常书面感。专业、简洁;
full:进一步压缩表达,可省略部分虚词,允许碎片句,使用短词替代。典型caveman风格;
ultra:大量缩写,如DB、auth、config、req、res、fn、impl;尽量去掉连接词;用箭头表达因果,如「X→Y」;能用一个词说明,就不用两个词。
举个例子:
- lite:「连接池会复用已经打开的数据库连接,而不是每次请求都新建一个,从而避免重复握手开销。」
- full:「连接池复用已打开的DB连接。不是每个请求都新建。省掉握手开销。」
- ultra:「连接池=复用DB连接。跳过握手→高并发更快。」
75%到底靠不靠谱?

没有模型架构改动,没有推理机制层面的压缩,caveman的本质就是一条精心编写的system prompt,约束的是AI的输出风格。
更关键的一点:作者Julius Brussee本人在HN讨论帖里主动澄清了,这个skill不针对hidden reasoning tokens和thinking tokens。模型在后台「想」的过程并不会因为caveman自动变短,它主要压缩的是最后说出来的那部分。
从仓库公开内容看,作者确实提供了benchmark脚本,也在README里列出了若干任务的token对比,区间从22%到87%,平均65%。但截至目前,外界仍难以仅凭仓库当前内容完整复核每一项结果的复现实验链条。
2024年的论文《The Benefits of a Concise Chain of Thought on Problem-Solving in Large Language Models》显示:当研究者要求模型使用更简洁的推理链时,GPT-3.5和GPT-4的平均回答长度下降了48.70%,而整体解题能力几乎没有明显下降。
开发者苦AI废话久矣
回到那个最初的问题:caveman到底有没有用?
如果把它当成一个严格意义上的「省钱工具」,那就需要更谨慎。它压缩的只是可见输出文本,并不触及hidden reasoning tokens,而后者往往才是Claude Code成本的大头。
但caveman真正值得关注的地方,不在于它是不是开出了一剂完美药方,而在于它本身就是一个信号。
当一个开发者把「让AI少说废话」这件事做成插件,放到GitHub上,被上千人认真讨论,在HN上爆火,事情的重点就已经变了。
它说明,AI工具的冗长,不再只是一个可以忍受的小毛病,而是严重到用户开始自己动手修正的程度。
在Hacker News上,开发者们的哀叹与成本挂钩:「我简直是在花15刀/100万Token的价钱,来阅读AI对我的道歉和寒暄。」
当大家宁愿让AI像「山顶洞人」一样说话,也不愿意继续为冗余输出多付token成本时,真正应当反思的也许是那些主流AI大厂——为什么直到今天,他们还没有把「克制」做成一种基础能力。
来源:AI中文社
2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,请使用WINRAR解压,如遇到无法解压的请联系管理员!
8. 精力有限,不少源码未能详细测试(解密),不能分辨部分源码是病毒还是误报,所以没有进行任何修改,大家使用前请进行甄别!
站长QQ:709466365 站长邮箱:709466365@qq.com